

OCR(Optical Character Recognition、光学文字認識)とは、「画像から文字を解析してテキストデータにする」技術の総称。
基本ブレがない機械文字の解析に特化しているが、機械学習を組み合わせれば手書きの文字もある程度は読めるようになるらしい。
しかし、少し前に試した感じ「画像から文字を読む」ではなく、読んだ上で確率の高そうなものを学習ファイルから引っ張ってくるイメージだったので、手書きの場合自由度はない。
また、どれだけ高精度でも100%にはならないため、「OCR → 手動修正UI → 保存」の処理は必須。
あくまで入力の補助として使うこと。
一番汎用的なTesseract(テッセラクト)をはじめ、代表的なものと特徴は知っておきたい。
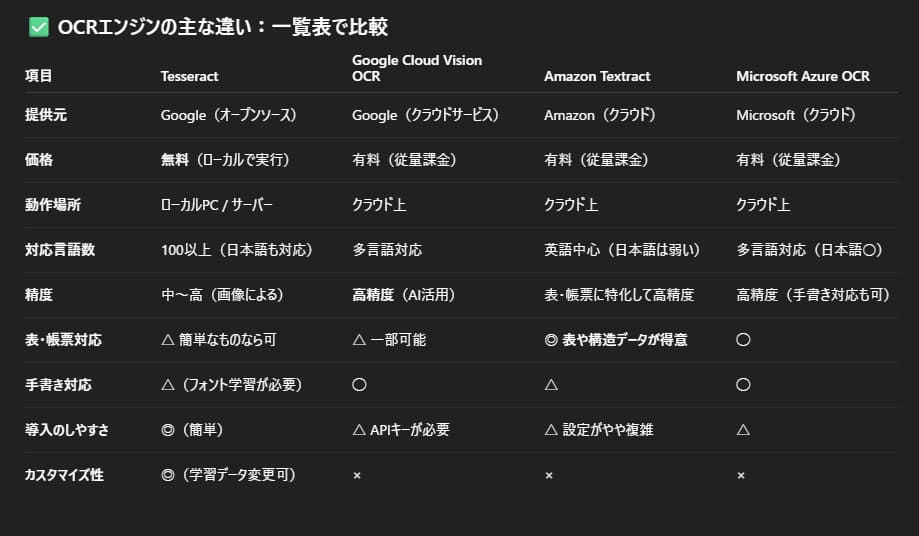
- Tesseract
- Google Cloud Vision OCR
- Amazon Textract
- Microsoft Azure OCR

この中で選択肢に入るなと思ったのは、「Tesseract」と「Google Cloud Vision OCR」のふたつ。
- Tesseract:すべて自分で設定を組む。ローカル(オフライン)でも動く
- Google Cloud Vision OCR:ある程度はGoogleのAIまかせ。ネット接続&API設定がいる
送信された画像を1枚まるっと解析するなら、Google Cloud Vision OCRのほうが精度が高い。
ただし、画像に含まれる行や列を意識して返してはくれないため、jsonに保存したい場合はやや面倒になることもある。
Tesseractをはじめとした各ツールは、解析範囲を絞っていくごとに精度が上がる。
「画像内のこの列をjsonのキーに合わせて保存したい」などの明確な方針があるなら、Tesseractですべて自分で組んだほうが、管理のしやすさなどを含め自由度は高い。
ただし以下の点には注意が必要。
- Tesseract:解析範囲を絞る都合上、画像のサイズが一定じゃないと機能しない。
- Google Cloud Vision OCR:AIでの処理なので、デバイスごとのスクショなどある程度のサイズのずれは考慮される。
つまり、送信される画像のサイズやレイアウトがコントロールできるならTesseract、不特定多数のユーザーまかせの画像が送られてくるならGoogle Cloud Vision OCRになる。
場合によっては、90%はTesseractでローカル処理して、高精度が必要な画像だけGoogle Cloud Vision OCRに投げるという合わせ技も有効。
- 画像を送信・手動修正するUIの作成(HTML + JavaScript)
- 受け取った画像をサーバーのTesseractなどで解析(python)
- 解析結果をデバイスに返して修正UIを表示(HTML + JavaScript)
- 保存(python)
はじめの画像送信UIはHTMLに書くが、それ以降は各操作を検知してjsで描画するため、HTML自体はとてもシンプルになる。
jsとサーバー側のpythonなどが長くなりがちなので、機能ごとにうまく分けられるように設計していくと良い。
HTMLは特に難しいところはないので、<body>部分だけ簡単に。
<body>
<h1>基金管理登録</h1>
<form id="upload-form">
<label>スクショ画像をアップロード:</label>
<input type="file" name="screenshot" accept="image/*" required>
<button type="submit">送信</button>
</form>
<div id="upload-result"></div>
<hr>
<div id="review-container"></div>
<button onclick="submitFinalData()">修正済みデータを保存</button>
<script src="{{ url_for('static', filename='js/payment.js') }}"></script>
</body>HTMLだけで送信するには<form>タグに、「action=”送信先URL” method=”POST” enctype=”multipart/form-data”」を必ず指定。これがないとflask側で受け取る request.files が空になる。<form>タグでファイルを送信する時の必須設定。
ただし今回は送信をjsで横取りして行うため、自動で設定されるので書かなくてもよい。
さらに画像を選択する<input>には、こちらもflaskでファイルが開けるように「name=”screenshot(任意の名前)”」を必ず指定。required で入力必須にしておく。
<div id=”upload-result”></div> に .pyのflaskルートに定義したmessageの文字列が、
<div id=”review-container”></div> にOCRの解析結果と手動修正のUIがJavaScriptから描画される想定。
最後にjsファイルを読み込む。
import os
import re
import json
import cv2
import pytesseract
import numpy as up
from PIL import Image
from flask import Flask, jsonify, request, render_template, send_from_directory
from werkzeug.utils import secure_filename- os:フォルダーの作成・パス操作
- re:OCRで日付と時刻がくっついて認識されるので、強制的にスペースを入れる
- json:pythonでjsonを扱えるように
- cv2:画像の読み込み・加工・色変換など
- pytesseract:pythonでTesseractを使うための指定
- numpy:cv2の画像処理で使う行や列のデータ操作
- PIL.Image:画像の読み込みや切り抜き・リサイズなど
- Flask:flaskアプリで作成。APIルートなどの指定
- werkzeug.utils:アップされたファイル名を安全な形式に変換
app = Flask(__name__)
UPLOAD_FOLDER = "static/payment-img"
REVIEW_FOLDER = "static/review-images"
DATA_FOLDER = "static/review-data"
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
os.makedirs(REVIEW_FOLDER, exist_ok=True)
os.makedirs(DATA_FOLDER, exist_ok=True)flaskアプリの定義。
各フォルダーのパスを指定、定数に入れる。なければ新規作成。
pytesseract.pytesseract.tesseract_cmd = r'C*\Program Files\Tesseract-OCR\tesseract.exe'pytesseractは内部で「tesseract.exe」を使用するため、そのファイル位置の指定。
MacやLinuxではTesseractがすでに組み込まれているため、指定しなくてもよい。
Windowsでは、githubなどからインストールして.exeがあるパスを指定する。
r’C*\Program Files\Tesseract-OCR\tesseract.exe’ はあくまでローカル環境でのパス。(変更していなければだいたいここ)
本番環境ではサーバーにTesseractをインストールしてパスをそこに合わせる。
ここまでが事前準備。
def normalize_text(text):
replacements = {
'0': '0', '1': '1', '2': '2', '3': '3', '4': '4',
'5': '5', '6': '6', '7': '7', '8': '8', '9': '9',
'ー': '-', '・': '', '\u3000': ' ', '$': 's', '@': '', 'TM': ''
}
for k, v in replacements.items():
text = text.replace(k, v)
return text.strip()今回作成したOCRでは、半角英数字と日本語のみを出力したかったため、大文字で読まれてしまった数字をあらかじめ半角数字に置き換える関数を作成しておく。
「 ‘\u3000’: ‘ ‘ 」は全角スペースを半角スペースにする指定。
for k, v in replacements.items():
text = text.replace(k, v)
return text.strip()ここは、OCRで読み取ったtextを、指定したreplacementsのkey, valueのペアに基づいて1つずつ置き換えていく処理。(pythonでは辞書型に対して.items()指定することでひとつずつ処理できる)
最後に先頭と末尾に挿入されているかもしれない空白や改行をstripで削除している。
def fix_date_spacing(text):
return re.sub(r'(\d{4}/\d{2}/\d{2})(\d{1,2}:\d{2}:\d{2})', r'\1 \2', text)2つめの関数では、日付と時刻が「”2025/08/0614:30:00″」のようにつながって出力された場合に強制的にスペースを入れる関数。
「re.sub()」は、文字列の中で、あるパターンにマッチするものを、別の文字列に置き換える。
- (\d{4}/\d{2}/\d{2}):4桁/2桁/2桁
- (\d{1,2}:\d{2}:\d{2}):1か2桁:2桁:2桁
この2つが隣り合っている場合のみ、’\1 \2’で間に半角スペースを入れるように指定している。
ちなみに\dは正規表現で、1桁の数字を意味している。
def process_image_and_generate_review_data(image_path):
image = Image.open(image_path)
cropped = image.crop((210, 355, 1070, 570))
cropped_cv = cv2.cvtColor(np.array(cropped), cv2.COLOR_RGB2BGR)
row_height = 45
rows = [cropped_cv[i:i + row_height, :] for i in range(0, cropped_cv.shape[0], row_height)][:5]
review_data = []
for idx, row_img in enumerate(rows):
file_name = f"row_{idx+1}.png"
img_path = os.path.join(REVIEW_FOLDER, file_name)
cv2.imwrite(img_path, row_img)
date_img = row_img[:, 0:220]
op_img = row_img[:, 230:480]
amount_img = row_img[:, 500:700]
from_img = row_img[:, 712:870]
date = normalize_text(fix_date_spacing(
pytesseract.image_to_string(date_img, config='--psm 7 --oem 3 -c tessedit_char_whitelist=0123456789:/')))
op = normalize_text(
pytesseract.image_to_string(op_img, config='--psm 7 -l jpn'))
amount = normalize_text(
pytesseract.image_to_string(amount_img, config='--psm 7 --oem 3 -c tessedit_char_whitelist=0123456789,'))
gray = cv2.cvtColor(from_img, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 180, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
from_user = normalize_text(
pytesseract.image_to_string(binary, config='--psm 7 -l eng --oem 3 -c tessedit_char_whitelist=abcdefghijklmnopqrstuvwxyz0123456789_-'))
normalized_path = image_path.replace("\\", "/")
review_data.append({
"row": idx + 1,
"image_path": f"/static/review-images/{file_name}",
"date": date,
"operation": "防衛戦予約料" if "防" in op else "入金",
"amount": amount,
"from": from_user,
"source_image": f"/{normalized_path}"
})
with open(os.path.join(DATA_FOLDER, "ocr_review.json"), "w", encoding="utf-8") as f:
json.dump(review_data, f, ensure_ascii=False, indent=2)Tesseractでは、「日付欄」「ユーザー名欄」などの意味的な解釈はできないため、どこがなんなのかを位置的に切って指定する必要がある。
解析の流れは、「画像を読み込む → 必要な個所を切り出す → 行の高さを指定し、必要回数繰り返して切り出す → その中からさらに列に分割 → 解析 → jsonに保存」
長いので少しずつ分割して解説。
def process_image_and_generate_review_data(image_path):
image = Image.open(image_path)
cropped = image.crop((210, 355, 1070, 570))
cropped_cv = cv2.cvColor(np.array(cropped), cv2.COLOR_RGB2BGR)
row_height = 45
rows = [cropped_cv[i:i + row_height, :] for i in range(0,cropped_cv.shape[0], row_height)][:5] まず関数の一番初めに、アップロードされた画像をPILのImage.open()で開く。
そのimageの中から必要な範囲だけ、image.crop(左, 上, 右, 下)をpx指定で切り出す。(画像をペイントなどで開いてpx位置を確認)
「PILのImageでは、画像そのものとして扱う」ため、人の目には見やすいが、色の変換や明るさの調整・ノイズ除去などの細かい前処理が指定できない。
そのため機械にも認識しやすいように、Numpy(asでnp)配列に変換する。
その後、1行の高さを45pxに指定。ここからが少し難しいが、
[cropped_cv[i:i + row_height, :]は、y軸の基点iからi + 45pxの範囲を切り出すという意味。最後の:はx軸はすべて含めるという意味。ちなみにxも指定するとなると、image[y1:y2, x1:x2] という書き方になる。
そしてfor i in range(0,cropped_cv.shape[0], row_height)]は、基点を45pxずつずらしていき都度iに代入するという繰り返し処理の指定になる。
つまり、繰り返し処理で45pxずつ基点iをずらしていき、その都度i + 45px切り出してrowsに代入している。
ちなみにcv2画像に.shape()を使うと、(height, width, channels)で画像のサイズ情報が返ってくる。
- shape[0] = height(高さ)
- shape[1] = widht(幅)
- shape[2] = RGB(色)
なので、(0,cropped_cv.shape[0], row_height)は、0pxから初めて縦方向に45pxずつ進めるよという指定になる。
[:5]は切り出された中から初めの5つだけを扱うという意味。切り出し処理的には5行以上切り出されている。 review_data = []
for idx, row_img in enumerate(rows):
file_name = f"row_{idx+1}.png"
img_path = os.path.join(REVIEW_FOLDER, file_name)
cv2.imwrite(img_path, row_img)review_data = [] は、解析結果のすべてをまとめて保存する用の空のリスト。
先ほどの処理で行を45pxずつ5回切り出したので、それをインデックス付きでループさせ、このインデックスに+1ずつさせることでファイル名を付けてREVIEW_FOLDERに保存している。
このインデックスがないとすべてrow.pngになってしまい最後の1つしか保存されなくなる。
ちなみにidx+1させる理由は、row_0.pngが視覚的によろしくないので、1から始まるようにしている。
cv2.imwrite()は、Numpy配列として扱っているデータをPNGやJPEG形式などのファイルに書き出す関数。
date_img = row_img[:, 0:220]
op_img = row_img[:, 230:480]
amount_img = row_img[:, 500:700]
from_img = row_img[:, 712:870]先ほどy軸に切ったので、これはx軸に切るという処理。
さらにここから解析にかけるため、あとで扱いやすいように分かりやすい変数名を付けている。
date = normalize_text(fix_date_spacing(pytesseract.image_to_string(data_img, config='--psm 7 --oem 3 -c tessedit_char_whitelist=0123456789:/')))
op = normalize_text(pytesseract.image_to_string(op_img, config='--psm 7 -l jpn'))
amount = normalize_text(pytesseract.image_to_string(amount_img, config='--psm 7 --oem 3 -c tesseract_char_whitelist=0123456789,'))
from_user = normalize_text(pytesseract.image_to_string(from_img, config='--psm 7 -l eng --oem 3 -c tessedit_char_whitelist=abcdefghijklmnopqrstuvwxyz0123456789_-'))この部分が実質的な解析の処理。
pytesseract.image_to_string() の部分で画像から文字を読み取る。
config はTesseractの設定で、–psm 画像をどう読み取るか?の設定になる。
- –psm 3:ページとして長文、複数段の文書をOCRする。デフォルト
- –psm 6:単一ブロックのテキストとしてOCRする。
- –psm 7:単一行のテキストとしてOCRする。
今のコードの場合は、すでに行と列で切り出しているので、–psm 7 に設定することで、誤認識を防いでいる。
–oem はOCRエンジンの指定。
- –oem 0:古いエンジン
- –oem 1:最新のエンジン
- –oem 2:古いエンジンのみ
- –oem 3:最新 + 古いエンジンから最適なほうを自動で選択
精度が高いのは1だが、0のほうが安定することもある。
3にしておけば自動で選んでくれるので、基本3でいい。
-c tessedit_char_whitelist= は読み取る文字の指定。
数字と: と / が指定してあれば、日付などを読み取るときに英語や日本語として読み取るような誤認が激減する。
なるべく設定するといい。
-l は読み取り言語の設定。
- -l eng:英語・数字・簡単な記号
- -l jpn:ひらがな・カタカナ・漢字
- -l jpn_vert:縦書きの日本語
- -l shi_sim:中国語
- -l eng+jpn:英語と日本語
この言語の設定には、言語データがインストールされている必要がある。
ローカルであればgithubから jpn.traineddata などをダウンロードし、C*\Program Files\Tesseract-OCR\tessedata の中に保存する。
ちなみに、4つの変数すべてに事前に定義しておいた normalize_text を適用させ、data 変数のみ fix_date_spacing関数を呼び出して、日付と時刻の間に半角スペースを強制的に入れるようにしている。
また、画像が鮮明でなかったり背景に模様が入ったりしている場合は、グレースケール化や白黒のみにする2値化などの前処理を入れることもある。
一度普通に通してみて特定箇所だけミスが頻発する場合などに使用するといい。
normalize_path = image_path.replace("\\","/")
review_data.append({
"row": idx + 1,
"image_path": f"/static/review-images/{file_name}",
"date": date,
"operation": "防衛戦予約料" if "防" in op else "入金",
"amount": amount,
"from": from_user,
"source_image": f"/{normalized_path}"
})OCRで読み取った1行分のデータをjson形式にして、事前に作成しておいた空のリストreview_data に追加する処理。
normalize_path は、Windows環境などで \ を使うパスをwebで使える / に変換する処理。
“row” は行番号で、1から始まるように+1している。
“image_path” は、自動でwebに配信されるように /static/ を付けて保存する。
{file_name} には先ほど定義した file_name = f”row_{idx+1}.png” が動的に入る。
“operation”は、解析結果の op に”防”が入っていたら”防衛戦予約料”に、それ以外は”入金”にする処理。
“source_image”は、あとでログの表示などに使用したいため、一番初めにユーザーがアップした画像のパスを指定している。
with open(os.path.join(DATA_FOLDER, "ocr_review.json"), "w", encoding="utf-8") as f:
json.dump(review_data, f, ensure_ascii=False, indent=2) 最後にreview_dataに入っているものをjson形式で保存する処理。
基本的な with open () as f: を使い、”ocr_review.json” ファイルを書き込みモード “w” で開いて、それを変数 f に代入。
json.dump() で review_data の中身を f に書き込む。ensure_ascii=False は日本語をユニコード文字列にせずそのまま書く、indent は保存したjsonにインデントを付ける。
これで一通りOCRの関数が読めるようになりました。
これまでで必要な関数の定義ができたので、これをスクショがアップされたflaskのルートに組み込んでいく。
@app.route("/upload-screenshot", methods=["POST"])
def upload_screenshot():
if "screenshot" not in request.files:
return jsonify({"status": "error", "message": "画像が選択されていません"}), 400
file = request.files["screenshot"]
if file.filename == "":
return jsonify({"status": "error", "message": "ファイル名が空です"}), 400
filename = secure_filename(file.filename)
save_path = os.path.join(UPLOAD_FOLDER, filename)
try:
image = Image.open(file.stream)
max_width = 1280
if image.width > max_width:
new_height = int(image.height * (max_width / image.width))
image = image.resize((max_width, new_height), Image.LANCZOS)
if image.mode != "RGB":
image = image.convert("RGB")
image.save(save_path, format="JPEG", quality=80)
process_image_and_generate_review_data(save_path)
return jsonify({"status": "success", "message": "✅ アップロード&OCR完了"})
except Exception as e:
return jsonify({"status": "error", "message": f"OCR処理中にエラー: {str(e)}"}), 500これも長いので分割して解説。
@app.route("/upload-screenshot", methods=["POST"])
def upload_screenshot():
if "screenshot" not in request.files:
return jsonify({"status": "error", "message": "画像が選択されていません"}), 400@app.route でflaskのルートを定義。
URLの /upload-screenshot にアクセスがあったとき、upload_screenshot() の関数を実行する。
methods=[“POST”] は、POSTメソッドだけ許可するという意味。
methods=[“GET”] では、URLのパラメータにくっついて送信されるため軽量なものしか処理できず今回のような画像を送る用途に向かない。(検索やページ切り替えなど、見せるだけでサーバーの状態を変えない操作向け)
[“POST”] メソッドでは、送信データはURLに表示されず、HTTPリクエストのボディ部分に入る。またバイナリデータ(0と1のみが羅列、機械が処理するためのデータ)も送れるため大容量で、画像やPDFなどの送信には必須になる。
データ保存やアップロードなどの、サーバーの状態を変える操作に向く。
そして、flaskでは送られてきたファイルは「request.files」に入る。
この request.files は辞書型で、キーはHTML側の入力フォームのname属性の値になる。(今回は、screenshot)
@app.route("/upload-screenshot", methods=["POST"])
def upload_screenshot():
if "screenshot" not in request.files:
return jsonify({"status": "error", "message": "画像が選択されていません"}), 400なので、if “screenshot” not in request.files: は、送られてきた request.files の辞書に screenshot キーがなかったら、return に書かれているエラーメッセージを返すという処理になる。
ちなみに jsonify はpythonの辞書やリストをJSON形式の文字列にして返す関数。
400は、不正なリクエストを意味している。
file = request.files["screenshot"]
if file.filename == "":
return jsonify({"status": "error", "message": "ファイル名が空です"}), 400これは request.files の中にある キー [“screenshot”] で取り出せる値(今回は送信されてきた画像)を 変数 file に代入するという意味。
さらにその取り出した値から filename を取得し、ファイル名が空だった場合は、return のエラーメッセージを返している。
JavaScript 側でもファイルが含まれていない送信などのエラーチェックは当然行っているが、JavaScript 自体は簡単に無効化できてしまうため、サーバー側でも必ずエラーチェックを入れる。(想定外のものでサーバーが落ちる危険もあるためセキュリティ上必須)
filename = secure_filename(file.filename)
save_path = os.path.join(UPLOAD_FOLDER, filename)secure_filename() は、flaskの werkzeug.utils に入っている関数(はじめのimportに記載)。
ユーザーがアップロードしたファイル名から、空白や記号を削除して安全な形式に変換する。
save_path は、はじめのフォルダー構成で定義した UPLOAD_FOLDER に filename を保存するための絶対パスを作っている。
try:
image = Image.open(file.stream)PILのImage.open() でアップロードされた画像を開く。それをimageに代入。
file.stream は、file のバイナリデータをストリーム形式で取り出すという指定。
今回のようなアップロードされた画像を保存せずに、リサイズからOCRまで即処理したいときや、大きなファイルを分割処理したいときなどに使う。

max_width = 1280
if image.width > max_width:
new_height = int(image.height * (max_width / image.width))
image = image.resize((max_width, new_height), Image.LANCZOS)送られてきたスクショ画像は、サイズが大きすぎて処理に時間がかかる + そのまま保存するとサーバーの容量が大きくなってしまうので、はじめにリサイズする。
max_width で指定した 1280px よりも横幅が大きかった場合は、縮小。
アスペクト比を保つために height は計算で決める。( max_width / image.width で倍率を出し、それを height に掛けている、小数は使えないため int で整数値化)
それをPILの .resize() で新しいサイズに変換。(Image.LANCZOS は補間方法の指定。LANCZOS は高品質優先)
if image.mode != "RGB":
image = image.convert("RGB")
image.save(save_path, format="JPEG", quality=80)PILの画像は mode(色)を持つ。これをRGBに統一させておくことで、OCR処理での色の不一致によるエラーなどを防ぐ。
もし image の mode が RGB じゃなかったら… .convert(“RGB”) で RGB にするという意味。
その後、.save() で、保存先は save_path、ファイル形式は 強制でJPEGに、quality は圧縮率、で保存。
process_image_and_generate_review_data(save_path)
return jsonify({"status": "success", "message": "✅ アップロード&OCR完了"})この保存パス(save_path)に事前に定義しておいたOCRの関数を呼び出すことで、文字の解析からJSONへの保存までが完了する。
またここでprintではなくJSON形式(return jsonify)で返しているのは、ページをリロードすることなくユーザーにアップロードが完了したことをUIに表示させたいから。(flaskで表示を変えるとなるとHTMLを返すしかなく、ページが強制リロードされてしまう)
このJSONを後のjsで取得し、HTMLの必要な個所だけ置き換えるようにしている。
except Exception as e:
return jsonify({"status": "error", "message": f"OCR処理中にエラー: {str(e)}"}), 500最後にtry文を閉めるexceptでエラー処理を書いて完成。
Exception ですべての例外をキャッチし、as e で発生した例外を e に代入。
それをJSON形式の出力に {str(e)} で文字として出力させている。500は、サーバー内部エラーを意味する。
ここまででHTMLでのUIとバックエンドでのOCRの解析処理が完成した。
ここからはHTMLからの画像送信とサーバーのOCR処理をつなげ(①)、そこからさらにHTMLに結果を返して修正UIを表示まで(②)をJavaScriptでつなげていく。
まずは①から。
document.getElementById("upload-form").addEventListener("submit", function (e) {
e.preventDefault();
const formData = new FormData(this);
fetch("/upload-screenshot", {
method: "POST",
body: formData,
})
.then(res => res.json())
.then(data => {
document.getElementById("upload-result").innerText = data.message;
if (data.status === "success") {
fetch("/static/review-data/ocr_review.json")
.then(res => res.json())
.then(newData => {
renderReviewRows(newData);
});
}
})
.catch(err => {
console.error("送信エラー:", err);
document.getElementById("upload-result").innerText = "❌ 送信に失敗しました";
});長いので分割して解説。
document.getElementById("upload-form").addEventListener("submit", function (e) {
e.preventDefault();HTMLの<form>に指定した「id=”upload-form”」を document.getElementById() で指定して、submit(送信) イベントに反応するように addEventListener() に設定。
ユーザーがHTMLの送信ボタンを押した時に、「function (e) {}」関数内の処理が実行される。
ちなみに「(e) 内にある e」は、ブラウザが「イベントが発生したときの情報」をまとめて渡してくれる特別な引数。
今回は<form>タグ内の送信ボタンのデフォルトであるページリロードを、jsで横取りして「e.preventDefault():」を指定することでページのリロードをさせないようにしている。(HTMLのみの送信は強制で再読み込み)
const formData = new FormData(this);
fetch("/upload-screenshot", {
method: "POST",
body: formData,
})const formData に new FormData(this); で、送信されてきた情報を格納している。
この「this」には、イベント元の<form>要素(正確には document.getElementByIdで指定した id=”upload-form”)が入る。
「new FormData(this); 」とすることで、そのフォーム内の<input>や<textarea>・<select>などすべて指定したname属性をキーにして詰め込んでくれる。
ここには画像などのバイナリデータも含まれる。
「fetch()」は、ブラウザからサーバーにHTTPリクエストを送るために使う。
今回のリクエスト先は「”/upload-screenshot”」であり、これは.pyで定義したflaskのルートである。
ここに送信データとリクエストがjsから渡されることでルート内の関数が実行される。
「method: “POST”」は、新しいデータを送信するときに使うメソッド。
「body: formData」は、サーバーに送るリクエストの中身。jsの場合は enctype が自動でmultipart/form-data になるのでHTMLの<form>タグに書く必要はない。
.then(res => res.json())
.then(data => {
document.getElementById("upload-result").innerText = data.message;
if (data.status === "success") {
fetch("/static/review-data/ocr_review.json")
.then(res => res.json())
.then(newData => {
renderReviewRows(newData);
});
}
})
.catch(err => {
console.error("送信エラー:", err);
document.getElementById("upload-result").innerText = "❌ 送信に失敗しました";
});通常の処理は、上から順に実行される(同期処理)。
ただし、fetch() のようにネットワーク通信などで時間がかかる処理は、すぐに結果を返せないため、結果が来たらあとで呼び出す仕組みを使う。(非同期処理)
そしてこの「サーバーからの結果が後で来る入れ物」を Promise と言う。(定型なので覚える)
そして「.then() 」は、Promiseに結果が届いたらこの関数を実行してね、という予約になる。(今回の場合は、promiseにresが届いたら、アロー関数でres.json() を実行する)
ここで登場する「res」は、サーバーからのレスポンスのこと。(Promiseはあくまで箱であり、その中身にResponseオブジェクトが入る)
res は本文を読むためのメソッドを持っており、「res.text():テキストとして読む」「res.json():JSONとして読む」で、JavaScriotのオブジェクトに変換してくれる。(このjsへの変換も時間がかかるため非同期処理となり、Promiseを再度返す)
そしてこのPromiseの中に入っているのが、「data」。(JSONをJavaScriptオブジェクトに変換したもの)
この「data」にはflaskで指定した「return jsonify()」の値がそのまま入っている。
# flaskで指定した /upload-screenshot 内のreturn jsonify
return jsonify({"status": "success", "message": "✅ アップロード&OCR完了"})
ということは…
data.status は、”success”
data.message は、”✅ アップロード&OCR完了” になる。
つまり、Promise に「data」が届いたら、HTMLの「id=”upload-result”」のテキスト内容を data.message に置き換えるという処理になる。
さらに data.status が “success” だった場合は、ページをリロードせずに結果を表示させるようにOCR結果の保存先のfetch(“/static/review-data/ocr_review.json”) から情報を取得して、HTMLを描画する関数で置き換えるようにしている。(関数は次項で解説)
また、「.catch」はPromiseを扱う処理内で発生したエラーをまとめて受け取る場所。
コンソールへのエラー表示と、UIに送信が失敗したことを表示させている。(.then():成功時の処理、.catch():失敗時の処理、なのでセットで使うこと)
ちなみに「res」や「data」は変数名(自由に付けられる)。
非同期処理の流れの中で、ひとつ前の.then() で何を返したかで得られる値が決まる。
ここまでで、「画像送信UIからアップロード → サーバーでOCR解析&結果保存 → 修正UIに解析の成功を表示」までできた。
ここからは修正UIに解析結果と共に修正の入力欄を表示させる関数をjsに書いていく。
let reviewData = [];
function renderReviewRows(newData) {
const container = document.getElementById("review-container");
container.innerHTML = "";
reviewData = newData;
newData.forEach((item, idx) => {
const rowDiv = document.createElement("div");
rowDiv.className = "row-block";
rowDiv.dataset.idx = idx;
rowDiv.innerHTML = `
<img src="${item.image_path}" alt="row_${item.row}">
<div class="input-row">
<div class="input-group date">
<label for="date-${idx}">日付</label>
<input id="date-${idx}" type="text" data-idx="${idx}" data-key="date" value="${item.date}" />
</div>
<div class="input-group small">
<label for="operation-${idx}">操作</label>
<input id="operation-${idx}" type="text" data-idx="${idx}" data-key="operation" value="${item.operation}" />
</div>
<div class="input-group small">
<label for="amount-${idx}">金額</label>
<input id="amount-${idx}" type="text" data-idx="${idx}" data-key="amount" value="${item.amount}" />
</div>
<div class="input-group small">
<label for="from-${idx}">名前</label>
<input id="from-${idx}" type="text" data-idx="${idx}" data-key="from" value="${item.from}" />
</div>
</div>
`;
container.appendChild(rowDiv);
});
// 入力の変更を反映
container.addEventListener("input", e => {
const idx = e.target.dataset.idx;
const key = e.target.dataset.key;
if (idx !== undefined && key) {
reviewData[idx][key] = e.target.value;
}
});
}
②も長いので分割して解説。
let reviewData = [];
function renderReviewRows(newData) {
const container = document.getElementById("review-container");
container.innerHTML = "";
reviewData = newData;修正UIのinputから値を取得して保存する方法もあるが、今回は「reviewData = [];」のリストをベースに表示から保存までを行う形とする。
また「 renderReviewRows(data) 」はHTMLを描画する関数であり、保存する関数はまた別で書くため reviewData = []; は関数内に含めないものとしている。
まずHTMLに指定しておいた「id=”review-container”」を container に代入。ここに修正UIが表示される。
この container に対して、「.innerHTML = “”; 」を指定して、表示内容をリセット。
そこから呼び出し元(ひとつ前の項)で定義した「newData」を受け取り、それを「reviewData」のリストに代入する。(保存用)
newData.forEach((item, idx) => {
const rowDiv = document.createElement("div");
rowDiv.className = "row-block";
rowDiv.dataset.idx = idx;先ほど取得した newData に「.forEach」メソッド(配列の要素を一つずつ取り出して処理する)を適用し、item を idx 付きで取り出す。(item = { 保存した配列 }, idx = 0 になる)
1行分取り出すごとに document.createElement(“div”) で、新しいdiv要素を生成。(メモリ上に作っただけ)それを「rowDiv」に代入。
この rowDiv に「.className」で “row-block” というCSSクラス名を設定。
さらに「dataset.idx」で data-set=”0″ という属性を設定します。(0の部分には .forEachで取得したidxが入る)
dataset は data- * 属性にアクセスするメソッド。
dataset.idx は、data-idx=” ”
dataset.key は、data-key=” “
dataset.userNameは、data-user-name=” ” がHTMLに付与される。
逆にHTML側のdata属性もdatasetで読み込める。
(- ハイフンはjs側ではキャメルスケールになる)
rowDiv.innerHTML = `
<img src="${item.image_path}" alt="row_${item.row}">
<div class="input-row">
<div class="input-group date">
<label for="date-${idx}">日付</label>
<input id="date-${idx}" type="text" data-idx="${idx}" data-key="date" value="${item.date}" />
</div>
<div class="input-group small">
<label for="operation-${idx}">操作</label>
<input id="operation-${idx}" type="text" data-idx="${idx}" data-key="operation" value="${item.operation}" />
</div>
<div class="input-group small">
<label for="amount-${idx}">金額</label>
<input id="amount-${idx}" type="text" data-idx="${idx}" data-key="amount" value="${item.amount}" />
</div>
<div class="input-group small">
<label for="from-${idx}">名前</label>
<input id="from-${idx}" type="text" data-idx="${idx}" data-key="from" value="${item.from}" />
</div>
</div>
`;
container.appendChild(rowDiv);
});メモリ上に作成した<div>要素である rowDiv に「.innerHTML = “(バッククォート)」を適用させ、複数行のHTMLを組み立てている。
${idx} には .forEach で取得した idx番号が入り、”${item.image_path}” や “row_${item.row}” には同じく .forEachから取得した item内にあるキーが割り当てられている。
このitemのキーには、flaskのOCR解析処理で保存した1行分のデータである以下のものが入る。
normalized_path = image_path.replace("\\", "/")
review_data.append({
"row": idx + 1,
"image_path": f"/static/review-images/{file_name}",
"date": date,
"operation": "防衛戦予約料" if "防" in op else "入金",
"amount": amount,
"from": from_user,
"source_image": f"/{normalized_path}"
})つまり、OCR解析処理では5行分の結果をJSONに保存していたので、このjsの処理を行うことで「取得したdataに.forEach」が適用されることで5行分のHTMLが順に生成されることになる。
最後にHTMLの id=”review-container” を代入した container に「.appendChild(rowDiv);」をすることで、HTMLに追加表示させている。
// 入力の変更を反映
container.addEventListener("input", e => {
const idx = e.target.dataset.idx;
const key = e.target.dataset.key;
if (idx !== undefined && key) {
reviewData[idx][key] = e.target.value;
}
});
}最後のこれは、container(id=”review-container”)内の input イベント(テキスト入力欄に文字が入力される)を都度キャッチしてアロー関数を実行する処理。
「e.target」はイベントが起きた要素を指す。
つまり、
e.target.dataset.idx; は、何行目か?
e.target.dataset.key; は、日付欄か?金額欄か?…etc
if文で data-idx と data-key が空でないことを確認したうえで、reviewData の所定の値をリアルタイムで変更している。(将来 data-idx や data-key を含まない要素が追加されたときの保険。なくても動く)
JavaScriptでは、if (key)だけでもこの値が”truthy:真”と見なせるかどうかを判定してくれる。
一見 if (idx && key)だけでもいい気もするが、数値の0が入ったときも”falsy:偽”扱いになってしまうため、if (idx !== undefined && key) としておくのが安全。
最後の保存は、その後の扱いで大きく変わるので簡単に解説する。
まずHTMLに設置しておいた保存ボタン。
<button onclick="submitFinalData()">修正済みデータを保存</button>これに指定しておいた「submitFinalData()」関数をjsに記述する。
function submitFinalData() {
fetch("/submit-final-donations", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify(reviewData)
})
.then(res => res.json())
.then(result => {
if (result.status === "success") {
alert(result.message);
const container = document.getElementById("review-container");
container.innerHTML = "";
reviewData = [];
} else {
alert("保存失敗: " + result.message);
}
})
.catch(err => {
console.error("保存エラー:", err);
alert("保存中にエラーが発生しました。");
});
}ボタンが押されたら、まず fetch(“/submit-final-donations”)で flask の保存エンドポイントを呼び出す。(事前に定義している前提)
method: “POST” でデータを送信するモードに設定し、「 headers: {“Content-Type”: “application/json”},」でこのデータはJSONであることをサーバーに伝える。
さらに「body: JSON.stringify(reviewData)」を指定して、reviewData 内の配列をJSON文字列に変換して送信している。
送信結果をresで受取り、res.json() でJSONをjsで読めるように変換。
その中からstatus を取り出し “success” であれば、alert ポップアップで message を表示。
さらに「id=”review-container”」をcontainer に代入し、「.innerHTML = “”;」で修正UIを初期化。
reviewData = []; もすべて削除し空にしている。
statusの値が “success” 以外だった場合は、保存失敗とmessage のみをalertポップアップで表示させて、修正UIはそのまま残している。
以上
サーバーがLinux環境と仮定して進めると、
sudo nano update
sudo apt install tesseract-ocrこれがTesseract本体のインストール。
sudo apt install tesseract-ocr-jpnこれで自動的に日本語のデータが所定位置に配置される。
tesseract --list-langsで、jpn などがでれば言語データのインストールも成功している。

